
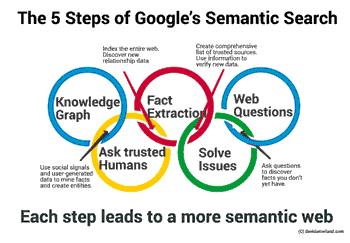
جستجوی معنایی در موتور های جستجو چیست
جستجوی معنایی یا هوشمندانه در سدد است که بتواند موتور های جستجو را محبوب کاربران کند
موتورهای جستجوی معنایی (جستجوی معنایی در وب)
امروز حجم وسیعی از داده های rdf روی وب وجود دارد و میزان این داده ها روز به روز افزایش می یابد. از آنجا که موتورهای جستجو دروازه های ورود به وب معنایی هستند.
ضرورت یک موتور جستجوی کارا با زمان پاسخگویی کم و حجم ایندکس کم و بهنگام رسانی سریع و مقاوم در برابر اسپم و سایتهای جعلی کاملا احساس میشود.در هر موتور جستجو فازهای پویش و ایندکس گذاری و جستجو و رتبه بندی نتایج برای ارائه به کاربر وجود دارد که برای وب اسناد کارهای زیادی در زمینه موتور جستجو صورت گرفته است.
برای تعمیم الگوریتم ها و روشهای جستجوی وب اسناد به وب داده ها چندین بازبینی در فازهای مختلف موتور جستجو لازم است. از جمله در فاز ایندکس گذاری که باید ایندکس ها بر اساس هر المان rdf و هر ترکیب خاصی از آنها قابلیت جستجو داشته باشند.
خدمات اصلی عصر اطلاعات به کاربران چیست؟؟
در فاز رتبه بندی هم چون زمینه و نوع لینک ارتباطی بین منابع مهم است بنابراین الگوریتم های رتبه بندی وب اسناد باید مورد بازبینی کامل قرار گیرند. پرسشهای مختلفی میتوان روی وب داده ها انجام داد که میتوان آنها را به سه دسته بزرگ :
پرسش کلمه کلیدی و پرسش (شبه)ساخت یافته و پرسش آنتولوزیکی تقسیم کرد.
در این موتور جستجوی معنایی سعی میکنیم برای هر نوع پرسش از کاراترین روش با کمترین تعداد lookup روی ایندکس ها و گسترش بهینه ی گراف جوابها استفاده کنیم که در عین پاسخگویی دقیق به پرسش ، کاربر در کمترین زمان ممکن به بهترین پاسخ دسترسی داشته باشد.
تعدادی موتور جستجو ایجاد شده اند که با دنبال کردن لینکهای RDF،داده های پیوندی را از وب پویش میکنند و امکان اجرای پرسش روی داده های جمع آوری شده فراهم می کنند. این موتورهای جستجو داده ها را از هزارها منبع داده یکپارچه میکنند و اینگونه مزایای معماری باز و استاندارد داده های پیوندی را در مقابل اجتماعهای وب 2.0 (که مبتنی بر منبع داده های ثابت با اینترفیسهای متناسب است )را نشان می دهد.
موتورهای جستجویی مثل Sig.ma وFalcons و SWSE قابلیتهای جستجو بر اساس کلمه کلیدی را فراهم میکند و عملکردی شبیه موتورهای جستجوی تجاری مثل گوگل و یاهو دارند. کاربر کلمه کلیدی را جستجو میکند و لیست نتایج مرتبط با جستجو به او نشان داده می شود.
در Falcon کاربران میتوانند نتایج جستجو را بر اساس کلاس فیلتر کنند مثلا فقط افراد یا موجویتهایی که متعلق به یک زیر کلاس خاص از افراد مثلا ورزشکاران است را انتخاب کنند. این موتورهای جستجوی معنایی دید خلاصه از موجودیت هایی که کاربر از نتایج جستجو انتخاب میکند(به همراه سایر داده های ساخت یافته جمع آوری شده از وب و ارتباط به موجودیتهای مرتبط) را فراهم می آورد.
در sig.ma قالب های نمایش برای نمایش موجودیتهای خاص به کاربر وجود دارد تا نتایج به صورت بهتری به کاربر ارائه شوند. کاربر امکان تعریف منابع داده مورد اعتمادش را در sig.ma دارد تا بحث کیفیت داده نیز به نوعی مرتفع گردد.
موتور جستجوی VisiNav پرسشهای پیچیده را روی داده های پیوندی پاسخ میدهد. برای مثال پاسخ به پرسش “URL همه بلاگهایی را به من نشان بده که نویسندگان آنها را Berners-Lee میشناسد.”
در این موتور جستجو 54 نتیجه درست بر میگرداند ولی در گوگل و یاهو تنها صفحات وبی بازیابی می شوند که در مورد Berners-Lee هستند.
sig.ma و VisiNav و SWSE و Falcon قابلیت جستجو برای انسان را فراهم میکنند. ایندکس های کاربرد-گرا مثل Sindice و Swoogle و watson کتابخانه هایی را فراهم میکنند که از طریق آنها کاربردهای داده های پیوندی قادرند اسناد RDF که به یک URI خاص اشاره می کنند یا شامل کلمات کلیدی خاصی هستند را باز گردانند.
uberblic سرویسی است که فراتر از یافتن داده های وب عمل میکند و به برنامه نویسان امکان یکپارچه سازی داده ها را میدهد. این سرویس بصورت یک لایه میانی بین منتشر کننده و مصرف کننده ی داده قرار میگیرد و داده ها را در یک انبار داده مرکزی مجتمع میکند و برنامه نویسان از طریق توابع کتابخانه ای به این انبار داده دسترسی دارند. yahoo و Google نیز ایندکس گذاری و بازیابی اطلاعات ساخت یافته را آغاز کرده اند.
شما می توانید آموزش سئو را در سایت سئو ۶ مطالعه نمایید.

دیدگاهتان را بنویسید